

多言語音声データを用いた日本語音声合成モデルを開発
- 編集部
- 2024年10月9日
AIニュースの要約
- NABLAS株式会社が、多言語音声データを活用した日本語音声合成モデルを開発。
- 数秒間の音声データと日本語テキストを用いることで、流暢な日本語音声の合成が可能に。
- モデルは英語や中国語、韓国語など他言語の声質を保持したまま日本語の発音を生成。
- 発話困難者支援、言語学習、エンターテインメント分野での応用が期待される。
- 今後はリアルタイム翻訳や音声変換技術の開発にも注力。
AIニュースの背景(推測)
近年、音声合成技術は多様な業界で需要が高まっています。特にAI技術の進化に伴い、自然で人間らしい音声生成が求められる場面が増加しています。これにより、音声合成が提供する新しい体験や支援の可能性が広がっています。これまでの音声合成技術は特定の言語に依存していたため、多言語話者の音声を日本語に変換することが困難でした。そのため、用意された音声データの限界が存在しており、さらなる発展と応用が求められていたと考えられます。NABLAS株式会社は、こうした市場のニーズを捉え、多様な言語に対応した音声合成モデルの開発に取り組んだと推測されます。
AIニュースの内容(詳細)
NABLAS株式会社が開発した音声合成モデルは、数秒の多言語音声データを使用して流暢な日本語を生成することができる技術です。この技術の要点は、特定の言語に依存せず、様々な言語から取られた音声データを用いて日本語の音声モデルを生成できることにあります。これにより、エンターテインメント、教育、通訳サービスなど、さまざまな分野で有用性が向上します。
具体的には、本モデルはGoogle社の音声生成モデル「SoundStorm」を基にしており、これが高品質な音声合成を実現しています。データの収集も簡素化されており、多様な言語で数秒の音声をいくつか録音するだけで、日本語への音声合成が可能です。これにより、声優やアナウンサーの録音といった従来の手法からの脱却が期待されます。
活用例としては、発話に困難を抱える人々への支援としての使い方が挙げられます。自身の音声を用いてテキストを入力し、簡単に話すことができるため、発言する自信を持ってもらえる仕組みが実現します。また、言語学習や通訳の分野でも、特定の話者の声質を保持した日本語音声が生成されるため、学習者や通訳者がその声で何度も練習できる環境が提供されることが期待されます。
さらに、映画やゲームの制作においても、元の音声を利用して日本語吹き替えができるため、制作コストを削減しつつ、高品質なコンテンツが制作される道が開けます。
ビジネスで活用する方法・可能性
この多言語音声データを用いた日本語音声合成モデルは、ビジネスにおいてさまざまな活用方法と可能性を提供します。
まず、発話支援機器を扱う企業にとっては、大きな価値を持つ技術です。発話が困難な方々に向けた製品に本技術を組み込むことで、使用者は自分の声を持ちながらコミュニケーションを促進できます。これにより、顧客満足度の向上や新しい市場の開拓が期待できます。
次に、教育関連の企業やサービスもこの技術を活用できます。特に語学教育において、音声合成によってネイティブスピーカーのような発音を提供し、学習者が自信を持って会話練習を行えるよう支援することが可能になります。これにより、教育機関はより質の高い教育コンテンツを提供できるようになります。
エンターテインメント業界においては、本技術を映画制作やゲームのローカライズに活用することで、コスト削減と共に、様々な言語の音声を自然に吹き替えることができます。これにより、新しいコンテンツの制作や、国際的なマーケティング戦略を立てる上での柔軟性が生まれます。
さらに、通信業界における顧客サポートやAIチャットボットにも活用されます。日本語のテキストを瞬時に音声に変換して顧客に提供することで、よりスムーズなコミュニケーションが実現します。これにより、顧客の利便性向上や業務の効率化が図れます。
最後に、国内外のパートナーへの技術提供やライセンス契約を通じて、新たなビジネスモデルの構築が期待されます。音声合成技術は今後ますます多様な利用が進むと思われ、これにより企業の競争力を高める新たな機会が生まれるでしょう。
このように、多言語音声データを活用した日本語音声合成モデルは、様々なビジネス分野での活用が見込まれ、企業運営において革新をもたらす可能性があると言えます。
多言語音声データを用いた日本語音声合成モデルを開発数秒の音声データと日本語テキストだけで音声合成を可能にNABLAS株式会社2024年10月9日 10時00分1
AI総合研究所として活動するNABLAS株式会社 (本社 : 東京都文京区本郷、 代表取締役 所長 : 中山 浩太郎、 以下「当社」)は、多言語話者の声質を保持したまま、日本語テキスト音声合成を可能とするTTS ( Text-to-Speech ) モデルを開発しました。本モデルは、言語を問わない数秒の発話音声のデータを用いて、他言語話者の音声から流暢な日本語の音声合成が可能です。本技術により通訳や発話困難者への支援、映画や動画などのエンターテインメント作品の多言語化など、幅広い分野での応用が期待できます。▼音声データはこちらで試聴いただけます。
https://www.nablas.com/post/voice-synthesis-202410◾️開発の背景と概要
近年、様々な音声合成の活用が急速に広がり、自動音声案内や本の読み上げ、動画の吹き替えなど音声合成を活用した場面が増えてきました。しかし、これまでの音声合成では、声優やアナウンサーが事前に決められた文章を収録し、数分からなる音声データを元に声質を再現した音声モデルの構築が必要でした。また、日本語の音声合成の場合、日本語話者による音声モデルが必要となり、他言語の音声モデルでは流暢な日本語での音声合成は難しい状況でした。
これらの課題に対して、英語や中国語、韓国語など言語を問わない数秒の発話音声データから日本語テキストを読み上げ可能な音声合成モデルを構築し、日本語話者でなくても流暢な日本語による音声合成を可能としました。また、本モデルは、Google社が開発した音声生成モデル「SoundStorm」の構造をベースとして、当社開発の日本語対応音声生成モ
出典 PR TIMES
関連記事
 シンガポール開催のグローバル展示会「Big Data & AI World Asia 2024」にベクストが出展
シンガポール開催のグローバル展示会「Big Data & AI World Asia 2024」にベクストが出展
 日本最大規模のオープンイノベーション拠点「STATION Ai」が2024年10月31日にグランドオープン~11月2日から一般の方の利用が可能に~
日本最大規模のオープンイノベーション拠点「STATION Ai」が2024年10月31日にグランドオープン~11月2日から一般の方の利用が可能に~
 【英語圏展開】株式会社Garoopと松下由依アナウンサーがコラボした『AI YUI LESSON』英語版をリリース
【英語圏展開】株式会社Garoopと松下由依アナウンサーがコラボした『AI YUI LESSON』英語版をリリース
 【映像クリエイティブチャレンジ2024】生成AIと最先端の映像技術を用いて静岡市七間町の地域振興を目指す映像制作ワークショップを開催します! 12/27(金)17:00~@静岡東宝会館
【映像クリエイティブチャレンジ2024】生成AIと最先端の映像技術を用いて静岡市七間町の地域振興を目指す映像制作ワークショップを開催します! 12/27(金)17:00~@静岡東宝会館
 生成AIを活用した“人とAIが創り出す未来のファッションコンテスト”「TOKYO AI Fashion Week – 2025 S/S Contest」審査員が決定!
生成AIを活用した“人とAIが創り出す未来のファッションコンテスト”「TOKYO AI Fashion Week – 2025 S/S Contest」審査員が決定!
 リスキリングドットコム、若者・親子リスキリングで鈴木奈々がキャリアコンサルタントを目指す「NoMaps2024」のイベントレポートを公開
リスキリングドットコム、若者・親子リスキリングで鈴木奈々がキャリアコンサルタントを目指す「NoMaps2024」のイベントレポートを公開
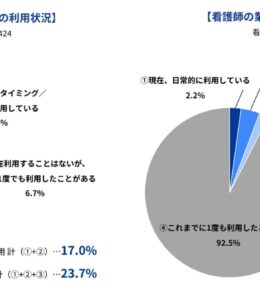 Indeedが「AIの業務利用に関する実態・意識調査【医療職(医師・看護師)編】」を実施。医師の約4人に1人、看護師の7.5%がAIの業務利用経験あり。
Indeedが「AIの業務利用に関する実態・意識調査【医療職(医師・看護師)編】」を実施。医師の約4人に1人、看護師の7.5%がAIの業務利用経験あり。
 【国内最大級】ブライティアーズ、100種類以上のAIツールが利用できる「All-in-One AI」β版をリリース
【国内最大級】ブライティアーズ、100種類以上のAIツールが利用できる「All-in-One AI」β版をリリース
 mooz.ai、最新AI「FLUX.1」を導入。画像生成アルゴリズムを刷新し表現力が大幅に向上
mooz.ai、最新AI「FLUX.1」を導入。画像生成アルゴリズムを刷新し表現力が大幅に向上
 「ターゲット:一般ユーザー」|生成AI連携の「SELFBOT」導入で、近畿大学のAIチャットボットが進化!
「ターゲット:一般ユーザー」|生成AI連携の「SELFBOT」導入で、近畿大学のAIチャットボットが進化!
 データサイエンティスト協会「11thシンポジウム~データサイエンスの最前線~」を11月11日開催
データサイエンティスト協会「11thシンポジウム~データサイエンスの最前線~」を11月11日開催
 【無料・無制限で利用できる生成AIプラットフォーム「リートン」】ローンチ以来、最大規模のリニューアルを実施
【無料・無制限で利用できる生成AIプラットフォーム「リートン」】ローンチ以来、最大規模のリニューアルを実施